CS 537
Lecture Notes
Paging
Contents
Paging
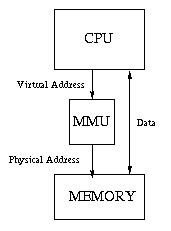
Most modern computers have special hardware called a memory management
unit (MMU). This unit sits between the CPU and the memory unit. Whenever
the CPU wants to access memory (whether it is to load an instruction or load or
store data), it sends the desired memory address to the MMU, which translates
it to another address before passing it on the the memory unit. The address
generated by the CPU, after any indexing or other addressing-mode arithmetic,
is called a virtual address, and the address it gets translated to by
the MMU is called a physical address.
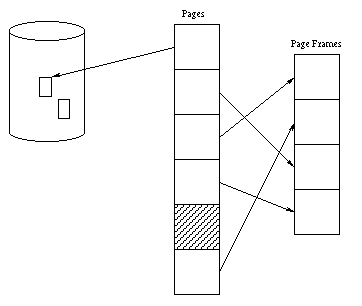
 Normally, the translation is
done at the granularity of a page. Each page is a power of 2 bytes
long, usually between 1024 and 8192 bytes. If virtual address p is
mapped to physical address f (where p is a multiple of the
page size), then address p+o is mapped to physical address
f+o for any offset o less than the page size. In other words,
each page is mapped to a contiguous region of physical memory called a page
frame.
Normally, the translation is
done at the granularity of a page. Each page is a power of 2 bytes
long, usually between 1024 and 8192 bytes. If virtual address p is
mapped to physical address f (where p is a multiple of the
page size), then address p+o is mapped to physical address
f+o for any offset o less than the page size. In other words,
each page is mapped to a contiguous region of physical memory called a page
frame.
The MMU allows a contiguous region of virtual memory to be mapped to page
frames scattered around physical memory making life much easier for the OS when
allocating memory. Much more importantly, however, it allows infrequently-used
pages to be stored on disk. Here's how it works: The tables used by the MMU
have a valid bit for each page in the virtual address space. If this
bit is set, the translation of virtual addresses on a page proceeds as normal.
If it is clear, any attempt by the CPU to access an address on the page
generates an interrupt called a page fault trap. The OS has an
interrupt handler for page faults, just as it has a handler for any other kind
of interrupt. It is the job of this handler to get the requested page into
memory.
In somewhat more detail, when a page fault is generated for page
p1, the interrupt handler does the following:
- Find out where the contents of page p1 are
stored on disk. The OS keeps this information in a table.
It is possible that this page isn't anywhere at all, in which case
the memory reference is simply a bug. In this case, the OS takes some
corrective action such as killing the process that made the reference
(this is source of the notorious message ``memory fault -- core dumped'').
Assuming the page is on disk:
- Find another page p2 mapped to some frame f
of physical memory that is not used much.
- Copy the contents of frame f out to disk.
- Clear page p2's valid bit so that any
subsequent references to page p2 will cause a page
fault.
- Copy page p1's data from disk to frame f.
- Update the MMU's tables so that page p1 is mapped
to frame f.
- Return from the interrupt, allowing the CPU to retry the instruction
that caused the interrupt.
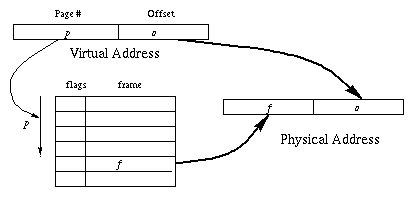
Page Tables
Conceptually, the MMU contains a page table which is simply an
array of entries indexed by page number.
Each entry contains some flags (such as the valid bit mentioned
earlier) and a frame number.
The physical address is formed by concatenating the frame number with the
offset, which is the low-order bits of the virtual address.
 There are two problems with this conceptual view.
First, the lookup in the page table has to be fast, since it is done
on every single memory reference--at least once per instruction executed
(to fetch the instruction itself) and often two or more times per instruction.
Thus the lookup is always done by special-purpose hardware.
Even with special hardware, if the page table is stored in memory, the table
lookup makes each memory reference generated by the CPU cause two
references to memory. Since in modern computers, the speed of memory
is often the bottleneck (processors are getting so fast that they spend
much of their time waiting for memory), virtual memory could make programs run
twice as slowly as they would without it.
We will look at ways of avoiding this problem in a minute, but first
we will consider the other problem:
The page tables can get large.
There are two problems with this conceptual view.
First, the lookup in the page table has to be fast, since it is done
on every single memory reference--at least once per instruction executed
(to fetch the instruction itself) and often two or more times per instruction.
Thus the lookup is always done by special-purpose hardware.
Even with special hardware, if the page table is stored in memory, the table
lookup makes each memory reference generated by the CPU cause two
references to memory. Since in modern computers, the speed of memory
is often the bottleneck (processors are getting so fast that they spend
much of their time waiting for memory), virtual memory could make programs run
twice as slowly as they would without it.
We will look at ways of avoiding this problem in a minute, but first
we will consider the other problem:
The page tables can get large.
Suppose the page size is 4K bytes and a virtual address is 32 bits long
(these are typical values for current machines).
Then the virtual address would be divided into a 20-bit page number and
a 12-bit offset (because 212 = 4096 = 4K), so
the page table would have to have 220 = 1,048,576 entries.
If each entry is 4 bytes long, that would use up 4 megabytes of memory.
And each process has its own page table.
Newer machines being introduced now generate 64-bit addresses.
Such a machine would needs a page table with 4,503,599,627,370,496 entries!
Fortunately, the vast majority of the page table entries are normally
marked ``invalid.'' Although the virtual address may be 32 bits long and
thus capable of addressing a virtual address space of 4 gigabytes, a
typical process is at most a few megabytes in size, and each megabyte
of virtual memory uses only 256 page-table entries (for 4K pages).
There are several different page table organizations use in actual
computers.
One approach is to put the page table entries in special registers.
This was the approach used by the PDP-11 minicomputer introduced in
the 1970's.
The virtual address was 16 bits and the page size was 8K bytes.
Thus the virtual address consisted of 3 bits of page number and 13 bits
of offset, for a total of 8 pages per process.
The eight page-table entries were stored in special registers.
[As an aside, 16-bit virtual addresses means that any one process could
access only 64K bytes of memory. Even in those days that was considered
too small, so later versions of the PDP-11 used a trick called ``split I/D
space.'' Each memory reference generated by the CPU had an extra bit
indicating whether it was an instruction fetch (I) or a data reference (D),
thus allowing 64K bytes for the program and 64K bytes for the data.]
Putting page table entries in registers helps make the MMU run faster
(the registers were much faster than main memory), but this approach has a
downside as well.
The registers are expensive, so it works for very small page-table size.
Also, each time the OS wants to switch processes, it has to reload the
registers with the page-table entries of the new process.
A second approach is to put the page table in main memory.
The (physical) address of the page table is held in a register.
The page field of the virtual address is added to this register to find
the page table entry in physical memory.
This approach has the advantage that switching processes is easy (all you
have to do is change the contents of one register) but it means that every
memory reference generated by the CPU requires two trips to memory.
It also can use too much memory, as we saw above.
A third approach is to put the page table itself in virtual memory.
The page number extracted from the virtual address is used as a virtual
address to find the page table entry. To prevent an infinite recursion,
this virtual address is looked up using a page table stored in physical memory.
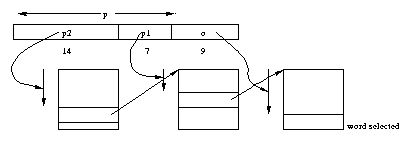
As a concrete example, consider the VAX computer, introduced in the late 70's.
The virtual address of the VAX is 30 bits long, with 512-byte pages (probably
too small even at that time!)
Thus the virtual address a consists of a 21-bit page number
p and a nine-bit offset o.
The page number is multiplied by 4 (the size of a page-table entry) and
added to the contents of the MMU register containing the address of
the page table. This gives a virtual address that is resolved using a
page table in physical memory to get a frame number f1.
In more detail, the high order bits of p index into a table
to find a physical frame number, which, when concatenated with the low bits
of p give the physical address of a word containing f.
The concatenation of f with o is the desired physical
address.
 As you can see, another way of looking at this algorithms is that the virtual
address is split into fields that are used to walk through a tree of
page tables.
The SPARC processor (which you are using for this course) uses a similar
technique, but with one more level: The 32-bit virtual address is
divided into three index fields and a 12-bit offset (see Figure 3-18 on
page 100 of the text).
The root of the tree is pointed to by an entry in a context table,
which has one entry for each process.
The advantage of these schemes is that they save on memory.
For example, consider a VAX process that only uses the first
megabyte of its address space (2048 512-byte pages).
Since each second level page table has 128 entries, there will be 16 of them
used. Adding to this the 64k bytes needed for the first-level page table,
the total space used for page tables is only 72K bytes, rather than
the 8 megabytes that would be needed for a one-level page table.
The downside is that each level of page table adds one more memory lookup
on each reference generated by the CPU.
As you can see, another way of looking at this algorithms is that the virtual
address is split into fields that are used to walk through a tree of
page tables.
The SPARC processor (which you are using for this course) uses a similar
technique, but with one more level: The 32-bit virtual address is
divided into three index fields and a 12-bit offset (see Figure 3-18 on
page 100 of the text).
The root of the tree is pointed to by an entry in a context table,
which has one entry for each process.
The advantage of these schemes is that they save on memory.
For example, consider a VAX process that only uses the first
megabyte of its address space (2048 512-byte pages).
Since each second level page table has 128 entries, there will be 16 of them
used. Adding to this the 64k bytes needed for the first-level page table,
the total space used for page tables is only 72K bytes, rather than
the 8 megabytes that would be needed for a one-level page table.
The downside is that each level of page table adds one more memory lookup
on each reference generated by the CPU.
A fourth approach is to use what is called an inverted page table.
(Actually, the very first computer to have virtual memory, the Atlas computer
built in England in the late 50's used this approach, so in some sense
all the page tables described above are ``inverted.'')
An ordinary page table has an entry for each page, containing the address
of the corresponding page frame (if any).
An inverted page table has an entry for each page frame, containing the
corresponding page number. To resolve a virtual address, the table
is searched to find an entry that contains the page number.
The good news is that an inverted page table only uses a fixed fraction of
memory.
For example, if a page is 4K bytes and a page-table entry is 4 bytes,
there will be exactly 4 bytes of page table for each 4096 bytes of physical
memory. In other words, less that 0.1% of memory will be used for page
tables.
The bad news is that this is by far the slowest of the methods, since
it requires a search of the page table for each reference.
The original Atlas machine had special hardware to search the table in parallel,
which was reasonable since the table had only 2048 entries.
All of the methods considered thus far can be sped up by using a trick
called caching.
We will be seeing many many more examples of caching used to speed things
up throughout the course. In fact, it has been said that caching is
the only technique in computer science used to improve performance.
In this case, the specific device is called a translation lookaside
buffer (TLB).
The TLB contains a set of entries, each of which contains a page number,
the corresponding page frame number, and the protection bits.
There is special hardware to search the TLB for an entry matching a
given page number.
If the TLB contains a matching entry, it is found very quickly and
nothing more needs to be done.
Otherwise we have a TLB miss and have to fall back on one of the
other techniques to find the translation. However, we can take that translation
we found the hard way and put it into the TLB so that we find it much more
quickly the next time. The TLB has a limited size, so to add a new entry,
we usually have to throw out an old entry. The usual technique is to
throw out the entry that hasn't been used the longest. This strategy, called
LRU (least-recently used) replacement is also implemented in hardware.
The reason this approach works so well is that most programs spend most
of their time accessing a small set of pages over and over again.
For example, a program often spends a lot of time in an ``inner loop'' in
one procedure. Even if that procedure, the procedures it calls, and so
on are spread over 40K bytes, 10 TLB entries will be sufficient to
describe all these pages, and there will no TLB misses provided the TLB
has at least 10 entries.
This phenomenon is called locality.
In practice, the TLB hit rate for instruction references is
extremely high.
The hit rate for data references is also good, but can vary widely for
different programs.
If the TLB performs well enough, it almost doesn't matter how TLB misses
are resolved.
The IBM Power PC and the HP Spectrum use inverted page tables organized
as hash tables in conjunction with a TLB.
The MIPS computers (MIPS is now a division of Silicon Graphics) get rid
of hardware page tables altogether. A TLB miss causes an interrupt, and
it is up to the OS to search the page table and load the appropriate entry
into the TLB. The OS typically uses an inverted page table implemented
as a software hash table.
Two processes may map the same page number to different page frames.
Since the TLB hardware searches for an entry by page number, there
would be an ambiguity if entries corresponding to two processes were
in the TLB at the same time.
There are two ways around this problem.
Some systems simply flush the TLB (set a bit in all entries marking them
as unused) whenever they switch processes.
This is very expensive, not because of the cost of flushing the TLB, but
because of all the TLB misses that will happen when the new process starts
running.
An alternative approach is to and a process identifier to each entry.
The hardware then searches on for the concatenation of the page number and
the process id of the current process.
We mentioned earlier that each page-table entry contains a ``valid'' bit
as well as some other bits.
These other bits include
- Protection
- At a minimum one bit to flag the page as read-only or read/write.
Sometimes more bits to indicate whether the page may be executed as
instructions, etc.
- Modified
- This bit, usually called the dirty bit, is set whenever
the page is referenced by a write (store) operation.
- Referenced
- This bit is set whenever the page is referenced for any reason,
whether load or store.
We will see in the next section how these bits are used.
Page Replacement
All of these hardware methods for implementing paging have one thing in common:
When the CPU generates a virtual address for which the corresponding page
table entry is marked invalid, the MMU generates a page fault
interrupt and the OS must handle the fault as explained
above.
The OS checks its tables to see why it marked the page
as invalid.
There are (at least) three possible reasons:
- There is a bug in the program being run.
In this case the OS simply kills the program (``memory fault -- core dumped'').
- Unix treats a reference just beyond the end of a process' stack as
a request to grow the stack. In this case, the OS allocates a page frame,
clears it to zeros, and updates the MMU's page tables so that the requested
page number points to the allocated frame.
- The requested page is on disk but not in memory.
In this case, the OS allocates a page frame, copies the page from disk into
the frame, and updates the MMU's page tables so that the requested
page number points to the allocated frame.
In all but the first case, the OS is faced with the problem of choosing
a frame.
If there are any unused frames, the choice is easy, but that will seldom
be the case.
When memory is heavily used, the choice of frame is crucial for decent
performance.
We will first consider page-replacement algorithms for a single process,
and then consider algorithms to use when there are multiple processes,
all competing for the same set of frames.
Frame Allocation for a Single Process
- FIFO
- (First-in, first-out) Keep the page frames in an ordinary queue, moving
a frame to the tail of the queue when it it loaded with a new page, and
always choose the frame at the head of the queue for replacement.
In other words, use the frame whose page has been in memory the longest.
While this algorithm may seem at first glance to be reasonable, it is
actually about as bad as you can get.
The problem is that a page that has been memory for a long time could equally
likely be ``hot'' (frequently used) or ``cold'' (unused), but FIFO treats
them the same way.
In fact FIFO is no better than, and may indeed be worse than
- RAND
- (Random) Simply pick a random frame.
This algorithm is also pretty bad.
- OPT
- (Optimum) Pick the frame whose page will not be used for the longest time
in the future.
If there is a page in memory that will never be used again, it's frame
is obviously the best choice for replacement. Otherwise, if (for example)
page A will be next referenced 8 million instructions in the
future and page B will be referenced 6 million instructions in the
future, choose page A.
This algorithm is sometimes called Belady's MIN algorithm after its
inventor.
I can be shown that OPT is the best possible algorithm, in the sense that
for any reference string (sequence of page numbers touched by a
process), OPT gives the smallest number of page faults.
Unfortunately, OPT, like SJF processor scheduling, is unimplementable
because it requires knowledge of the future.
It's only use is as a theoretical limit.
If you have an algorithm you think looks promising, see how it compares to
OPT on some sample reference strings.
- LRU
- (Least Recently Used) Pick the frame whose page has not been
referenced for the longest time.
The idea behind this algorithm is that page references are not random.
Processes tend to have a few hot pages that they reference over and over
again.
A page that has been recently referenced is likely to be referenced
again in the near future.
Thus LRU is likely to approximate OPT.
LRU is actually quite a good algorithm.
There are two ways of finding the least recently used page frame.
One is to maintain a list.
Every time a page is referenced, it is moved to the head of the list.
When a page fault occurs, the least-recently used
frame is the one at the tail of the list.
Unfortunately, this approach requires a list operation on every single
memory reference, and even though it is a pretty simple list operation,
doing it on every reference is completely out of the question, even
if it were done in hardware.
An alternative approach is to maintain a counter or timer,
and on every
reference store the counter into a table entry associated with the
referenced frame.
On a page fault, search through the table for the smallest entry.
This approach requires a search through the whole table on each page fault,
but since page faults are expected to tens of thousands of times less
frequent than memory references, that's ok.
A clever variant on this scheme is to maintain an n by n
array of bits, initialized to 0, where n is the number of page frames.
On a reference to page k, first set all the bits in row k
to 1 and then set all bits in column k to zero.
It turns out that if row k has the smallest value (when treated
as a binary number), then frame k is the least recently used.
Unfortunately, all of these techniques require hardware support and
nobody makes hardware that supports them.
Thus LRU, in its pure form, is just about as impractical as OPT.
Fortunately, it is possible to get a good enough approximation to LRU
(which is probably why nobody makes hardware to support true LRU).
- NRU
- (Not Recently Used) There is a form of support that is
almost universally provided by the hardware:
Each page table entry has a referenced bit that is set to 1 by the
hardware whenever the entry is used in a translation.
The hardware never clears this bit to zero, but the OS software can
clear it whenever it wants.
With NRU, the OS arranges for periodic timer interrupts (say once every
millisecond) and on each ``tick,'' it goes through the
page table and clears all the referenced bits.
On a page fault, the OS prefers frames whose referenced bits are still
clear, since they contain pages that have not been referenced since the
last timer interrupt.
The problem with this technique is that the granularity is too coarse.
If the last timer interrupt was recent, all the bits will be clear
and there will be no information to distinguished frames from each other.
- SLRU
- (Sampled LRU)
This algorithm is similar to NRU, but before
the referenced bit for a frame is cleared it is saved in
a counter associated with the frame and maintained in software by the OS.
One approach is to add the bit to the counter.
The frame with the lowest counter value will be the one that was
referenced in the smallest number of recent ``ticks''.
This variant is called NFU (Not Frequently Used).
A better approach is to shift the bit into the counter
(from the left).
The frame that hasn't been reference for the largest number of ``ticks''
will be associated with the counter that has the largest number of leading
zeros.
Thus we can approximate the least-recently used frame by selecting the frame
corresponding to the smallest value (in binary).
(That will select the frame unreferenced for the largest number of ticks,
and break ties in favor of the frame longest unreferenced before that).
This only approximates LRU for two reasons:
It only records whether a page was referenced during a tick, not when
in the tick it was referenced, and it only remembers the most recent n
ticks, where n is the number of bits in the counter.
We can get as close an approximation to true LRU as we like, at the cost of
increasing the overhead, by making the
ticks short and the counters very long.
- Second Chance
- When a page fault occurs, look at the page frames one at a time, in
order of their physical addresses. If the referenced bit is clear,
choose the frame for replacement, and return.
If the referenced bit is set, give the frame a ``second chance'' by clearing
its referenced bit and going on to the next frame (wrapping around to
frame zero at the end of memory).
Eventually, a frame with a zero referenced bit must be found, since at
worst, the search will return to where it started.
Each time this algorithm is called, it starts searching where it last
left off.
This algorithm is usually called CLOCK because the frames can
be visualized as being around the rim of an (analogue) clock, with the
current location indicated by the second hand.
We have glossed over some details here.
First, we said that when a frame is selected for replacement, we have
to copy its contents out to disk.
Obviously, we can skip this step if the page frame is unused.
We can also skip the step if the page is ``clean,'' meaning that it
has not been modified since it was read into memory.
Most MMU's have a dirty bit associated with each page.
When the MMU is setting the referenced bit for a page, it also sets
the dirty bit if the reference is a write (store) reference.
Most of the algorithms above can be modified in an obvious way to
prefer clean pages over dirty ones.
For example, one version of NRU always prefers an unreferenced page
over a referenced one, but with one category, it prefers clean over dirty
pages.
The CLOCK algorithm skips frames with either the referenced or the dirty
bit set.
However, when it encounters a dirty frame, it starts a disk-write operation
to clean the frame.
With this modification, we have to be careful not to get into an infinite loop.
If the hand makes a complete circuit finding nothing but dirty pages,
the OS simply has to wait until one of the page-cleaning requests finished.
Hopefully, this rarely if ever happens.
There is a curious phenomenon called Belady's Anomaly that comes
up in some algorithms but not others.
Consider the reference string (sequence of page numbers)
0 1 2 3 0 1 4 0 1 2 3 4.
If we use FIFO with three page frames, we get 9 page faults, including
the three faults to bring in the first three pages, but with more memory
(four frames), we actually get more faults (10).
Frame Allocation for Multiple Processes
Up to this point, we have been assuming that there is only active process.
When there are multiple processes, things get more complicated.
Algorithms that work well for one process can give terrible results
if they are extended to multiple processes in a naive way.
LRU would give excellent results for a single process, and all of the good
practical algorithms can be seen as ways of approximating LRU.
A straightforward extension of LRU to multiple processes still chooses
the page frame that has not been referenced for the longest time.
However, that is a lousy idea.
Consider a workload consisting of two processes.
Process A is copying data from
one file to another, while process B is doing a CPU-intensive
calculation on a large matrix.
Whenever process A blocks for I/O, it stops referencing its pages.
After a while process B steals all the page frames away from A.
When A finally finishes with an I/O operation, it suffers a series of
page faults until it gets back the pages it needs, then computes for
a very short time and blocks again on another I/O operation.
There are two problems here.
First, we are calculating the time since the last reference to a page
incorrectly.
The idea behind LRU is ``use it or lose it.''
If a process hasn't referenced a page for a long time, we take that as
evidence that it doesn't want the page any more and re-use the frame for
another purpose.
But in a multiprogrammed system, there may be two different reasons why
a process isn't touching a page: because it is using other pages, or
because it is blocked.
Clearly, a process should only be penalized for not using a page when
it is actually running.
To capture this idea, we introduce the notion of virtual time.
The virtual time of a process is the amount of CPU time it has used thus far.
We can think of each process as having its own clock, which runs only
while the process is using the CPU.
It is easy for the CPU scheduler to keep track of virtual time.
Whenever it starts a burst running on the CPU, it records the current
real time.
When an interrupt occurs, it calculates the length of the burst that
just completed and adds that value to the virtual time of the process
that was running.
An implementation of LRU should record which process owns each page,
and record the virtual time its owner last touched it.
Then, when choosing a page to replace, we should consider the difference
between the timestamp on a page and the current virtual time of the page's
owner.
Algorithms that attempt to approximate LRU should do something similar.
There is another problem with our naive multi-process LRU.
The CPU-bound process B has an unlimited appetite for pages, whereas
the I/O-bound process A only uses a few pages.
Even if we calculate LRU using virtual time, process B might occasionally
steal pages from A.
Giving more pages to B doesn't really help it run any faster, but taking
from A a page it really needs has a severe effect on A.
A moment's thought shows that an ideal page-replacement algorithm for
this particular load would divide into two pools.
Process A would get as many pages as it needs and B would get the rest.
Each pool would be managed LRU separately. That is, whenever B page faults,
it would replace the page in its pool that hadn't been referenced
for the longest time.
In general, each process has a set of pages that it is actively using.
This set is called the working set of the process.
If a process is not allocated enough memory to hold its working set,
it will cause an excessive number of page faults.
But once a process has enough frames to hold its working set, giving it
more memory will have little or no effect.
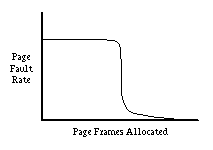
More formally, given a number t, the
working set with parameter t
of a process, denoted Wt, is the set of pages
touched by the process during its most recent t references to memory.
Because most processes have a very high degree of locality, the size of
t is not very important provided it's large enough.
A common choice of t is the number of instructions executed in 1/2
second.
In other words, we will consider the working set of a process to be
the set of pages it has touched during the previous 1/2 second of
virtual time.
The Working Set Model of program behavior says that the system
will only run efficiently if each process is given enough page frames to
hold its working set.
What if there aren't enough frames to hold the working sets of all processes?
In this case, memory is over-committed and it is hopeless to run
all the processes efficiently.
It would be better to simply stop one of the processes and give its pages
to others.
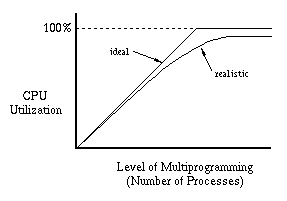
Another way of looking at this phenomenon is to consider CPU utilization as
a function of the level of multiprogramming (number of processes).
With too few processes, we can't keep the CPU busy.
Thus as we increase the number of processes, we would like to see the
CPU utilization steadily improve, eventually getting close to 100%.
Realistically, we cannot expect to quite that well, but we would still
expect increasing performance when we add more processes.
 Unfortunately, if we allow memory to become over-committed, something
very different may happen:
Unfortunately, if we allow memory to become over-committed, something
very different may happen:
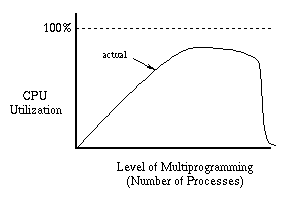 After a point, adding more processes doesn't help because the new processes
do not have enough memory to run efficiently. They end up spending all
their time page-faulting instead of doing useful work.
In fact, the extra page-fault load on the disk ends up slowing down
other processes until we reach a point where nothing is happening but
disk traffic.
This phenomenon is called thrashing.
After a point, adding more processes doesn't help because the new processes
do not have enough memory to run efficiently. They end up spending all
their time page-faulting instead of doing useful work.
In fact, the extra page-fault load on the disk ends up slowing down
other processes until we reach a point where nothing is happening but
disk traffic.
This phenomenon is called thrashing.
The moral of the story is that there is no point in trying to run more
processes than will fit in memory.
When we say a process ``fits in memory,'' we mean that enough page frames
have been allocated to it to hold all of its working set.
What should we do when we have more processes than will fit?
In a batch system (one were users drop off their jobs and expect them
to be run some time in the future), we can just delay starting a new
job until there is enough memory to hold its working set.
In an interactive system, we may not have that option. Users can
start processes whenever they want.
We still have the option of modifying the scheduler however.
If we decide there are too many processes, we can stop one or more
processes (tell the scheduler not to run them).
The page frames assigned to those processes can then be taken away and
given to other processes.
It is common to say the stopped processes have been ``swapped out'' by
analogy with a swapping system, since all of the pages of the stopped
processes have been moved from main memory to disk.
When more memory becomes available (because a process has terminated or
because its working set has become smaller) we can ``swap in'' one
of the stopped processes.
We could explicitly bring its working set back into memory, but it
is sufficient (and usually a better idea) just to make the process
runnable. It will quickly bring its working set back into memory simply
by causing page faults.
This control of the number of active processes is called load control.
It is also sometimes called medium-term scheduling as contrasted
with long-term scheduling, which is concerned with deciding when to
start a new job, and short-term scheduling, which determines how to
allocate the CPU resource among the currently active jobs.
It cannot be stressed too strongly that load control is an essential
component of any good page-replacement algorithm.
When a page fault occurs, we want to make a good decision on which page
to replace.
But sometimes no decision is good, because there simply are not enough
page frames.
At that point, we must decide to run some of the processes well rather
than run all of them very poorly.
This is a very good model, but it doesn't immediately translate into an
algorithm.
Various specific algorithms have been proposed.
As in the single process case, some are theoretically good but unimplementable,
while others are easy to implement but bad.
The trick is to find a reasonable compromise.
- Fixed Allocation
-
Give each process a fixed number of page frames.
When a page fault occurs use LRU or some approximation to it, but only
consider frames that belong to the faulting process.
The trouble with this approach is that it is not at all obvious how to
decide how many frames to allocate to each process.
If you give a process too few frames, it will thrash.
If you give it too many, the extra frames are wasted; you would be
better off giving those frames to another process, or starting another
job (in a batch system).
In some environments, it may be possible to statically estimate the
memory requirements of each job.
For example, a real-time control system tends to run a fixed collection
of processes for a very long time.
The characteristics of each process can be carefully measured and the
system can be tuned to give each process exactly the amount of memory
it needs.
Fixed allocation has also been tried with batch systems:
Each user is required to declare the memory allocation of a job when
it is submitted.
The customer is charged both for memory allocated and for I/O traffic,
including traffic caused by page faults.
The idea is that the customer has the incentive to declare the optimum
size for his job.
Unfortunately, even assuming good will on the part of the user, it can
be very hard to estimate the memory demands of a job.
Besides, the working-set size can change over the life of the job.
- Page-Fault Frequency (PFF)
-
This approach is similar to fixed allocation, but the allocations are
dynamically adjusted.
The OS continuously monitors the fault rate of each process, in page faults
per second of virtual time.
If the fault rate of a process gets too high, either give it more pages
or swap it out.
If the fault rate gets too low, take some pages away.
When you get back enough pages this way, either start another job (in
a batch system) or restart some job that was swapped out.
This technique is actually used in some existing systems.
The problem is choosing the right values of ``too high'' and ``too low.''
You also have to be careful to avoid an unstable system, where you
are continually stealing pages from a process until it thrashes and then
giving them back.
- Working Set
-
The Working Set (WS) algorithm (as contrasted with the working set model)
is as follows:
Constantly monitor the working set (as defined above) of each process.
Whenever a page leaves the working set, immediately take it away from
the process and add its frame to a pool of free frames.
When a process page faults, allocate it a frame from the pool of free frames.
If the pool becomes empty, we have an overload situation--the sum of the
working set sizes of the active processes exceeds the size of physical
memory--so one of the processes is stopped.
The problem is that WS, like SJF or true LRU, is not
implementable.
A page may leave a process' working set at any time, so the WS algorithm
would require the working set to be monitored on every single memory
reference.
That's not something that can be done by software, and it would be
totally impractical to build special hardware to do it.
Thus all good multi-process paging algorithms are essentially approximations
to WS.
- Clock
-
Some systems use a global CLOCK algorithm, with all frames, regardless of
current owner, included in a single clock.
As we said above, CLOCK approximates LRU, so global CLOCK approximates
global LRU, which, as we said, is not a good algorithm.
However, by being a little careful, we can fix the worst failing of global
clock.
If the clock ``hand'' is moving too ``fast'' (i.e., if we have
to examine too many frames before finding one to replace on an average
call), we can take that as evidence that memory is over-committed and
swap out some process.
- WSClock
-
An interesting algorithm has been proposed (but not, to the best of my
knowledge widely implemented) that combines some of the best features
of WS and CLOCK.
Assume that we keep track of the current
virtual time VT(p) of
each process p.
Also assume that in addition to the reference and dirty bits maintained
by the hardware for each page frame i, we also keep track
of process[i] (the identity of process that owns the page
currently occupying the frame) and LR[i] (an approximation
to the time of the last reference to the frame).
The time stamp LR[i] is expressed as the last reference time
according to the virtual time of the process that owns the frame.
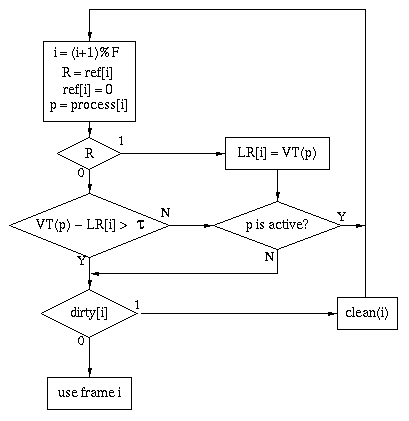 In this flow chart, the WS parameter (the size of the window in
virtual time used to determine whether a page is in the working set)
is denoted by the Greek letter tau.
Like CLOCK, WSClock walks through the frames in order, looking
for a good candidate for replacement, cleaning the reference
bits as it goes.
If the frame has been referenced since it was last inspected, it
is given a ``second chance''.
(The counter LR[i] is also updated to indicate that page
has been referenced recently in terms of the virtual time of its
owner.)
If not, the page is given a ``third chance'' by seeing whether it
appears to be in the working set of its owner.
The time since its last reference is approximately calculated by
subtracting LR[i] from the current (virtual) time.
If the result is less than the parameter tau,
the frame is passed over.
If the page fails this test, it is either used immediately or scheduled
for cleaning (writing its contents out to disk and clearing the
dirty bit) depending on whether it is clean or dirty.
There is one final complication:
If a frame is about to be passed over because it was referenced recently,
the algorithm checks whether the owning process is active, and
takes the frame anyhow if not.
This extra check allows the algorithm to grab the pages of processes
that have been stopped by the load-control algorithm.
Without it, pages of stopped processes would never get any ``older''
because the virtual time of a stopped process stops advancing.
In this flow chart, the WS parameter (the size of the window in
virtual time used to determine whether a page is in the working set)
is denoted by the Greek letter tau.
Like CLOCK, WSClock walks through the frames in order, looking
for a good candidate for replacement, cleaning the reference
bits as it goes.
If the frame has been referenced since it was last inspected, it
is given a ``second chance''.
(The counter LR[i] is also updated to indicate that page
has been referenced recently in terms of the virtual time of its
owner.)
If not, the page is given a ``third chance'' by seeing whether it
appears to be in the working set of its owner.
The time since its last reference is approximately calculated by
subtracting LR[i] from the current (virtual) time.
If the result is less than the parameter tau,
the frame is passed over.
If the page fails this test, it is either used immediately or scheduled
for cleaning (writing its contents out to disk and clearing the
dirty bit) depending on whether it is clean or dirty.
There is one final complication:
If a frame is about to be passed over because it was referenced recently,
the algorithm checks whether the owning process is active, and
takes the frame anyhow if not.
This extra check allows the algorithm to grab the pages of processes
that have been stopped by the load-control algorithm.
Without it, pages of stopped processes would never get any ``older''
because the virtual time of a stopped process stops advancing.
If no suitable frame is discovered in a complete circuit of the clock
hand, every page in memory is in the working set of some process.
Thus when WSClock cannot find a free frame going around the entire
clock, it stops some process.
solomon@cs.wisc.edu
Mon Nov 3 13:53:19 CST 1997
Copyright © 1996 by Marvin Solomon. All rights reserved.