Here we report on two different results:
The test were performed on 2 different kernel versions on an 8-way Netfinity 8500R with 700MHZ PIII and 2MB caches. The kernel versions wereNote that this is still work in progress and that
results only represent our current status.
PROC_CHANGE_PENALTY as described
in the MQ writeup is a mechanism to control movements of threads across
different processors. In general a thread is only moved from a source processor
to a target processor, if the thread's preemption goodness (wrt thread
running on the target processor) is at least PROC_CHANGE_PENALTY.Intuitively,
a higher PROC_CHANGE_PENALTY should
cause the individual run queues to become more isolated and reduce the
number of thread migrations. This could be either good (reduce overhead,
maintain cache affinity) or bad (priority inversion affecting application
progress) for performance.
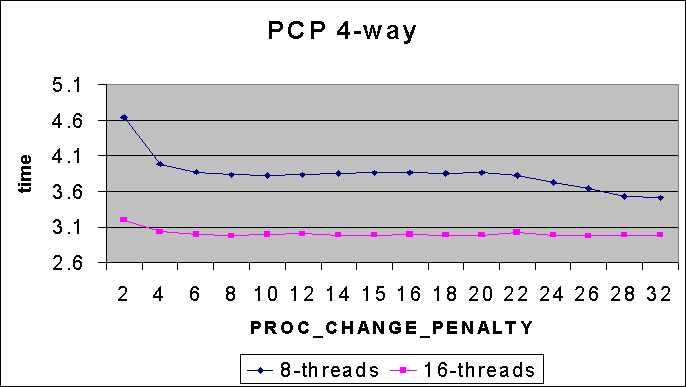
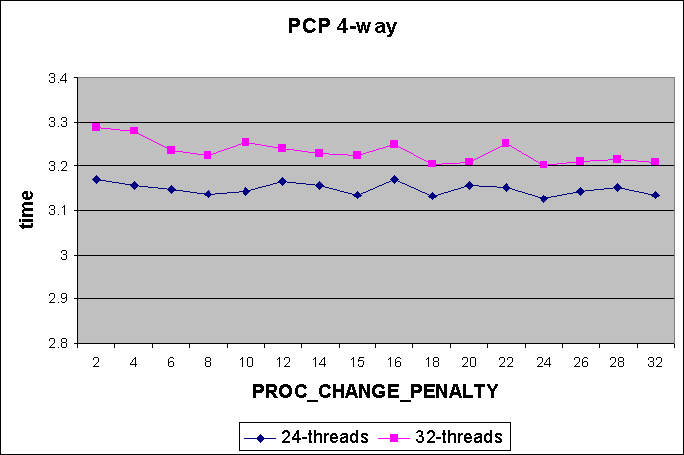
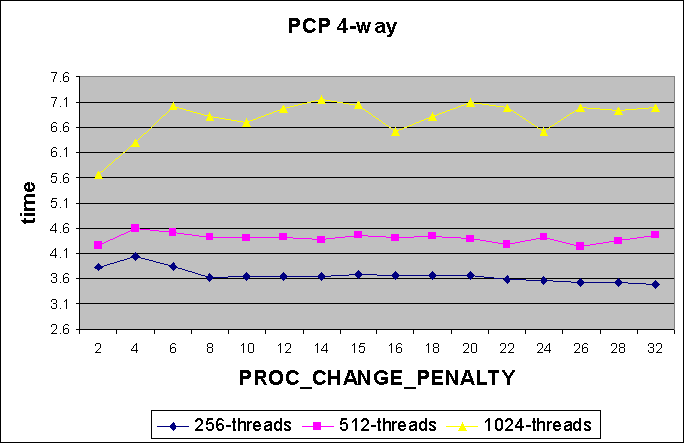
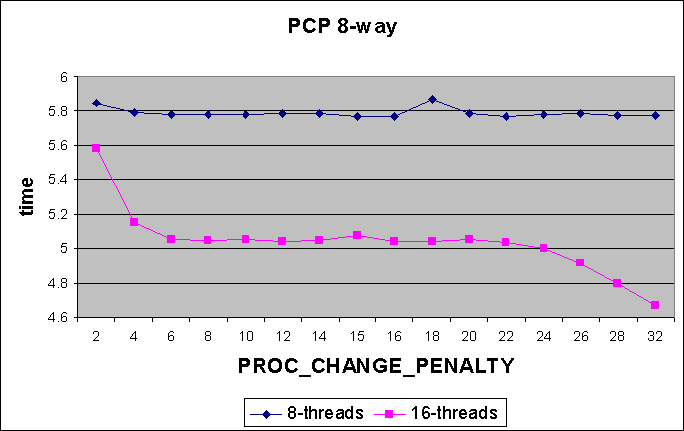
The first set of graphs shows the effect of different PROC_CHANGE_PENALTY
values
on different thread counts while running the reflex benchmark. Measurements
are shown for both 8-way and 4-way systems. It is expected that the effect
of PROC_CHANGE_PENALTY (henceforth
called PCP) is best seen when the number of threads (Nt) is somewhat greater
than the number of processors (Ncpus). If Nt is less than Ncpus, thread
migration will occur anyway (as preemption goodness is measured against
an idle thread). If Nt is very large, a local cpu runqueue candidate will
almost always be found.
4-way
8-way
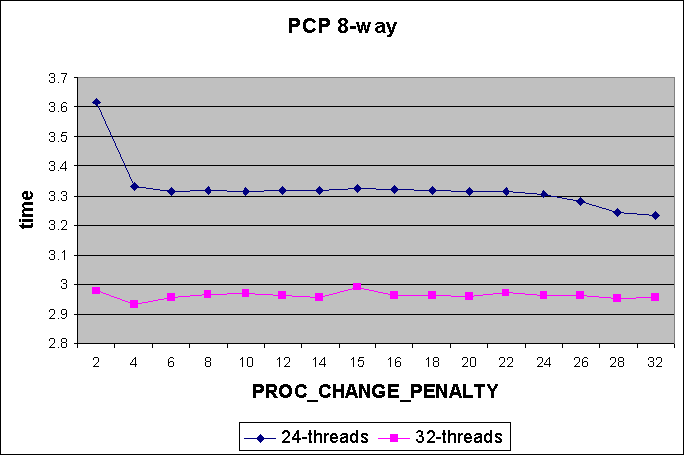
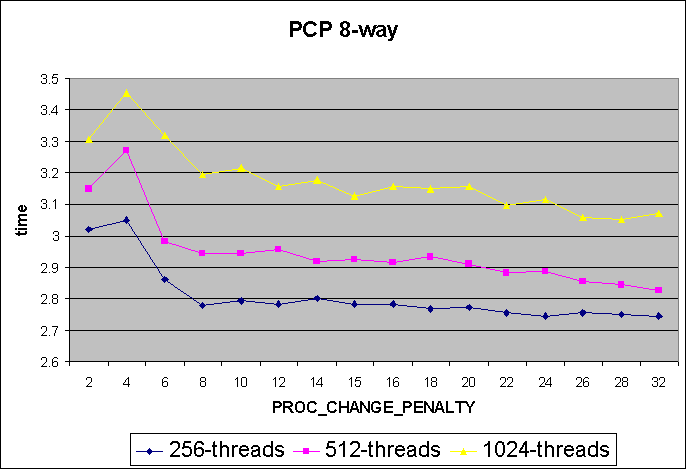
Observations
For both the 8-way and 4-way systems:
# concurrently runnable threads = 12, # CPUs = 8
| Counters | |||||||
| PCP | 1 | 2 | 3 | 4 | 5 | (4+5) | 6 |
| 6 | 23.82 | 13.05 | 11.50 | 23.51 | 1.10 | 24.61 | 27.26 |
| 15 | 23.75 | 13.03 | 11.49 | 23.34 | 1.09 | 24.44 | 27.06 |
| 24 | 23.55 | 12.91 | 11.39 | 23.60 | 0.98 | 24.59 | 26.86 |
| 32 | 22.29 | 12.18 | 10.71 | 23.64 | 0.51 | 24.15 | 25.16 |
| 40 | 22.36 | 12.22 | 10.75 | 24.12 | 0.52 | 24.63 | 25.65 |
# concurrently runnable threads = 8, #CPUs = 8
| Counters | |||||||
| PCP | 1 | 2 | 3 | 4 | 5 | (4+5) | 6 |
| 6 | 67.58 | 30.67 | 22.32 | 17.41 | 26.84 | 44.25 | 82.33 |
| 15 | 67.38 | 30.63 | 22.30 | 17.32 | 26.65 | 43.97 | 81.83 |
| 24 | 66.82 | 30.52 | 22.18 | 17.70 | 25.74 | 43.44 | 79.67 |
| 32 | 61.98 | 28.59 | 20.44 | 19.11 | 20.52 | 39.63 | 68.22 |
| 40 | 62.26 | 28.72 | 20.51 | 18.82 | 20.63 | 39.45 | 68.20 |
Explanation of counters (labelling same as in the data sets above)
% of schedule() calls in which
1 : there exists a better remote thread
2 : lock succeeded on remote queue
3 : remote value still better after lock acquired
1-2 => multiple remote runqueue's examined per stack list creation
% of reschedule_idle() calls in which
6 : some target cpu exists (for preemption)
4 : target cpu == task_cpu (lock implicitly held)
5 : target cpu != task_cpu AND lock succeeded on target runqueue
4+5 => reschedule occurs
6 => reschedule would occur (from a scheduling policy perspective)
but for lock acquisition problems
Conclusions from Expts 1 & 2 :
The graphs from Expt 1 show that increasing PROC_CHANGE_PENALTY does
not adversely affect performance (us/round either remains the same or decreases).
The data from Expt 2 shows this to be caused by the reduction in the
number of migrations (3,4+5). It has already been observed that MQ1 is
quite aggressive in terms of thread migrations (compared to vanilla). Hence,
the two datasets show that reducing thread migration by increasingly isolating
the CPU runqueues is a desirable feature (for the current MQ1).
The two experiments strengthen the case for pool based scheduling enhancements
to MQ. While there may not be significant performance benefits to the pooling
itself, there is no harm either. If good heuristics for maintaining cache
affinity, reducing overhead etc. can be found, pool based scheduling could
give even more benefits than the current MQ1. Load balancing is one such
heuristic which is examined next.
For each benchmark, different pool sizes (1,2,4,8) are run with load
balancing turned on and off. Load balancing on (lb-on) demonstrates the
benefits/costs of equalizing runqueue lengths. Load balancing off (lb-off)
shows the effect of pooling alone.
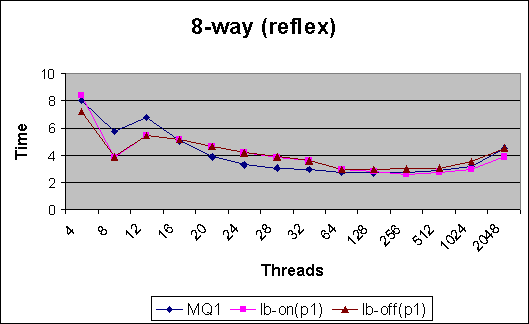
Reflex Benchmark Results :
Pool Size 1
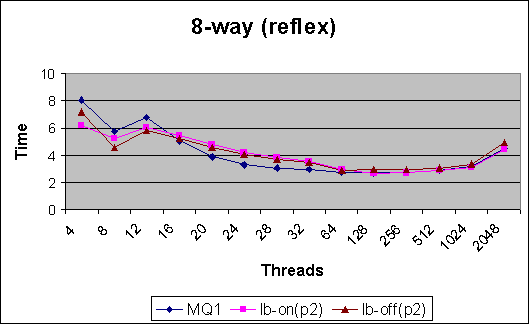
Pool Size 2
Pool Size 4
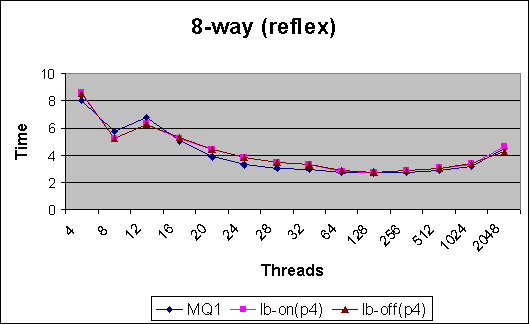
Pool Size 8

Observations (for reflex) :
For reflex, even with the simple heuristics currently in place, load balancing does marginally better for high thread counts and marginally worse on low thread counts. The difference in values is not significant in itself. But the results pave the way for better balancing heuristics.
Chatroom Benchmark results :
Pool Size 1
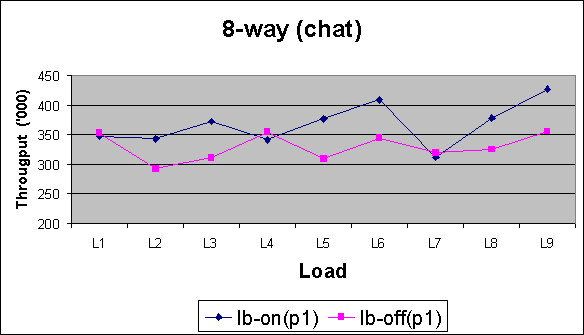
Pool Size 2
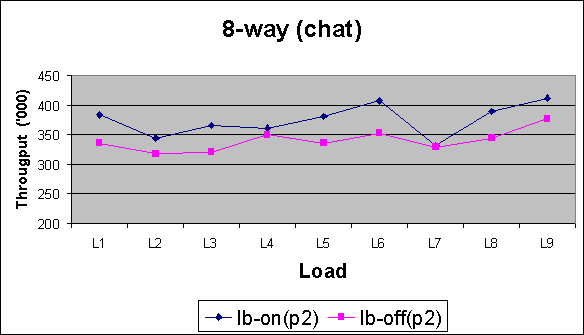
Pool Size 4

Pool Size 8
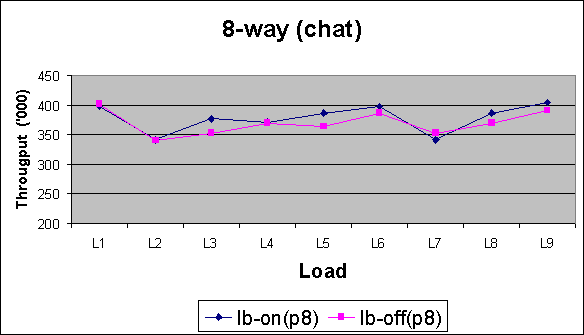
X-Axis
L1 = 10 rooms/ 100 messages
L2 = 10 rooms/ 200 messages
L3 = 10 rooms/ 300 messages
L4 = 20 rooms/ 100 messages
L5 = 20 rooms/ 200 messages
L6 = 20 rooms/ 300 messages
L7 = 30 rooms/ 100 messages
L8 = 30 rooms/ 200 messages
L9 = 30 rooms/ 300 messages
Observations (for chatroom) :
For chatroom, lb-on shows more significant improvement in performance.across all runs (different number of rooms and messages). Smaller pool sizes show more benefits.