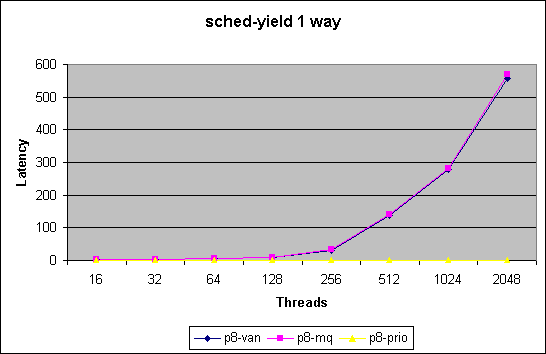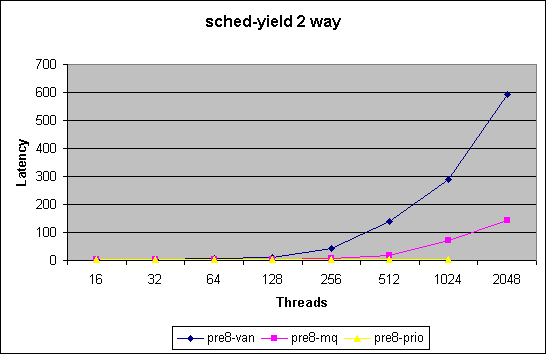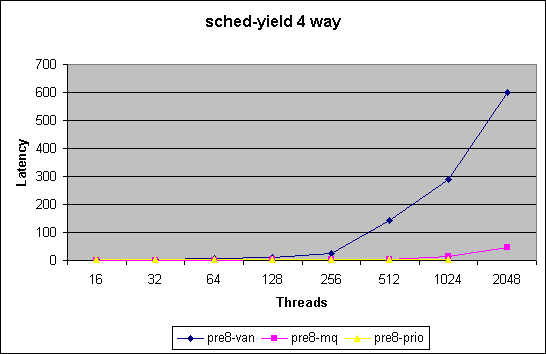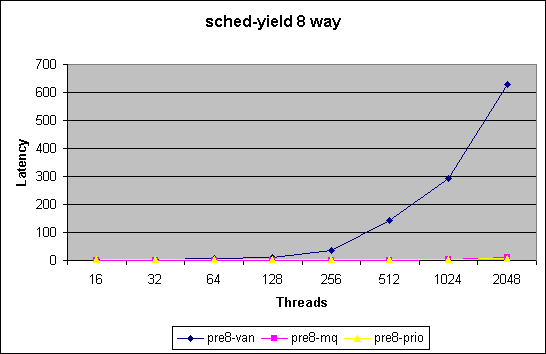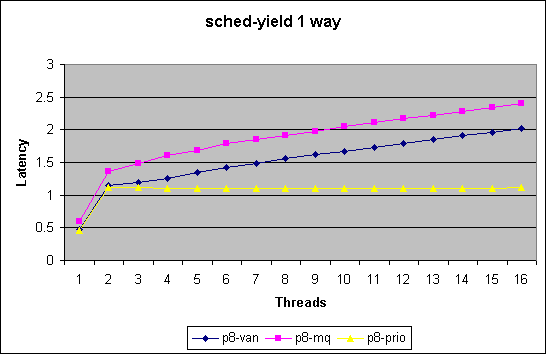
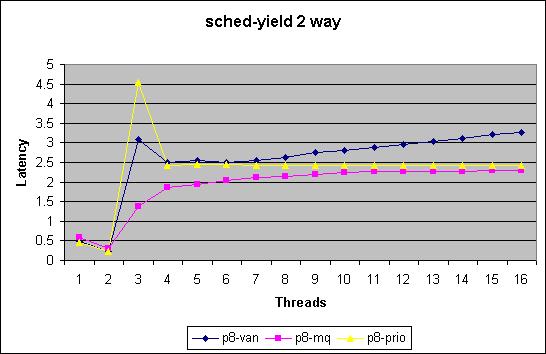
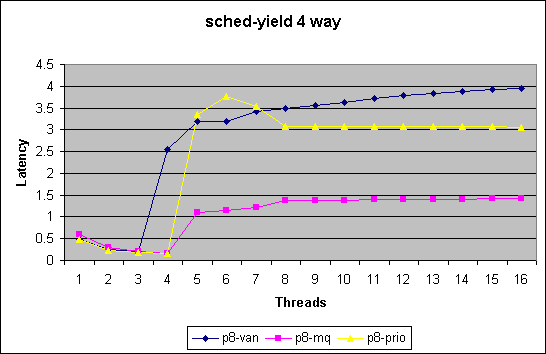
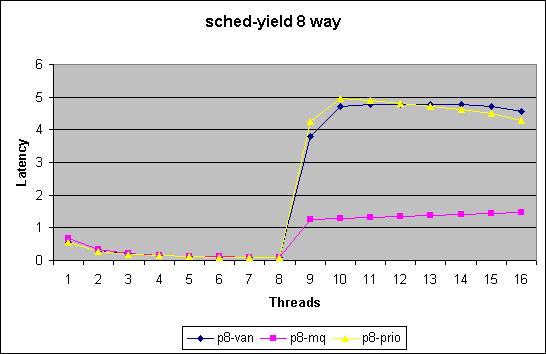
At the current time we are utilizing two benchmarks to test and evaluate the impact on our scheduler modifications
We also provide some initial results/behaviour for load balancing.The test were performed on 3 different kernel versions on an 8-way Netfinity 8500R with 700MHZ PIII and 2MB caches.
We chart here two sets of plots comparing the 3 kernel version.
The first measures latency per yield in
micro seconds for 1 upto 8way systems in the low end thread counts (<=
16 threads).
The second set of plots is for all thread
counts upto 2048.
Missing numbers indicate that test did not converge to within 95% confidence
interval.
Note in this benchmark we merely measure how quickly we can get through
the schedule() function. For thread counts below the number of cpus in
the systems does not force a schedule call due to recent optimizations.
This benchmark does not measure impact of reschedule_idle. With a thread
count higher then number of cpus this benchmark will force lock contention
in the non-MQ case.
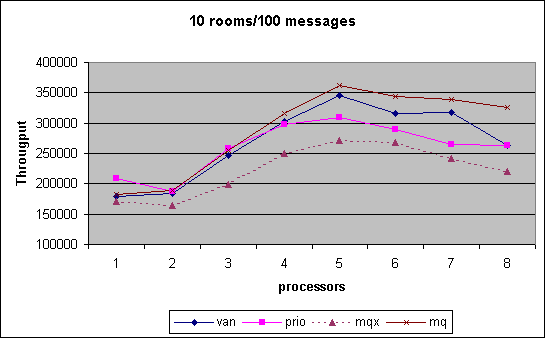
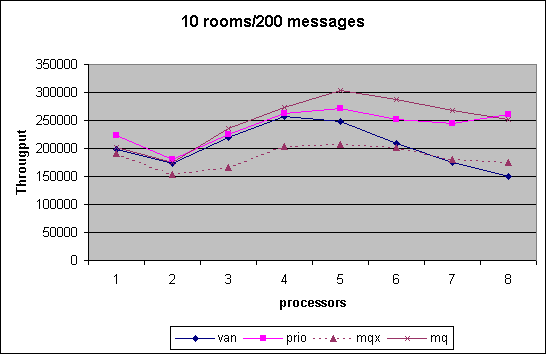
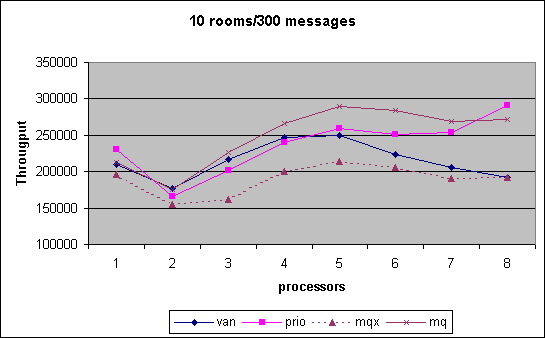
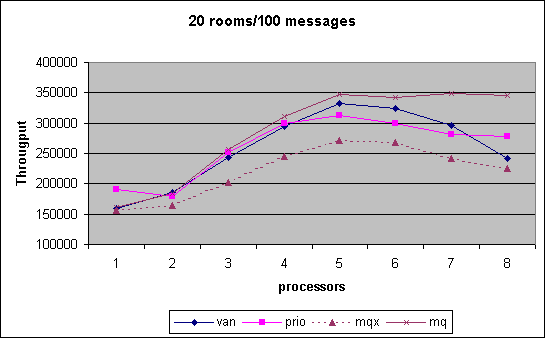
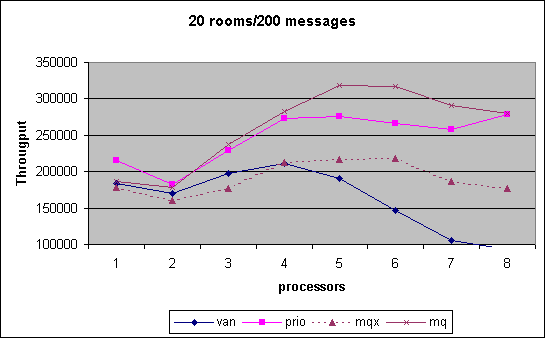
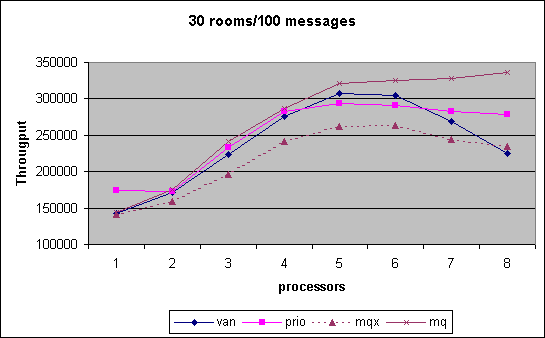
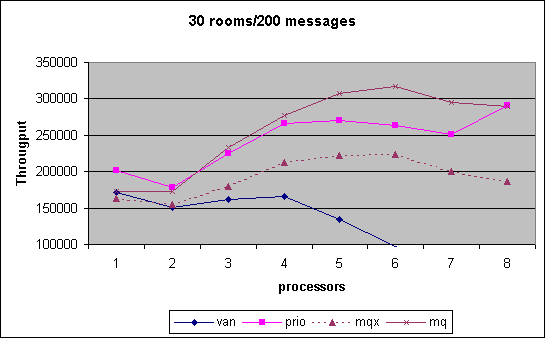
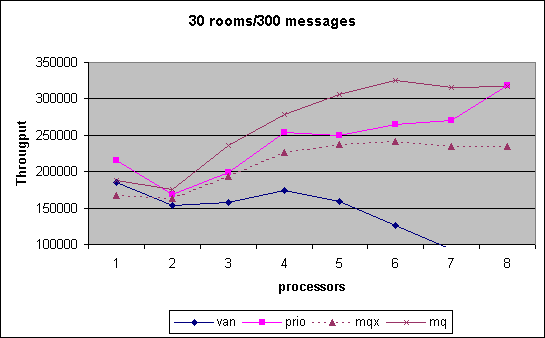
In the Chatroom we measured cpu scalability for various combinations of chatrooms established by room count and number of messages exchanged. The performance number obtained is the throughput of messages that we can generate, i.e. the higher the better. As can be seen, the MQ scheduler outperform pretty much through out the entire spectrum of tests the other versions. Note that in the last month we had the controversy that MQ scheduler performance had dropped significantly. We show that data for that interim version under MQX. Changes between MQX and MQ where that the preemption priority was off by one triggering additional reschedule events and secondly an additional preemption goodness was inserted to ensure that the information collected was not stale during reschedule_idle().
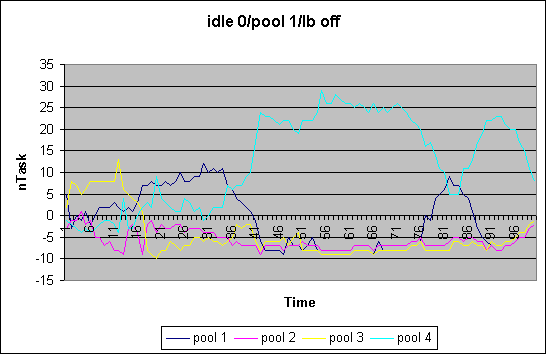
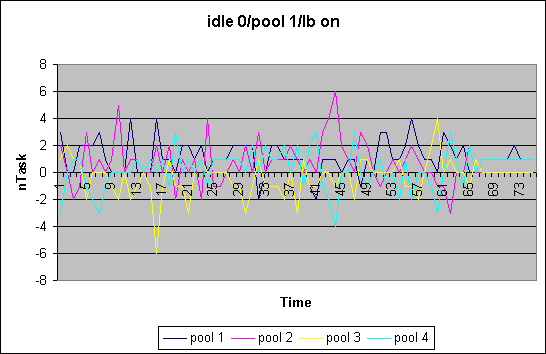
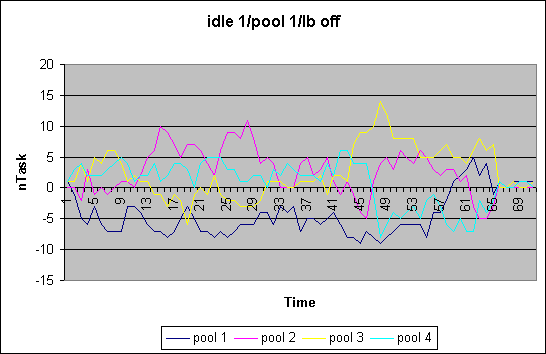
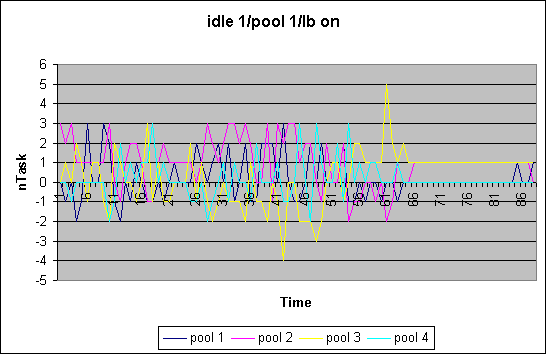
In our first load balancing approach we extended the MQ scheduler to restrict scheduling within a defined set of cpus. Frequently, rather than on every schedule and reschedule_idle() call we try to rebalance the load in all the queues based on some load function. We measured queue length over time and used "1" as the load function for each thread (ofcourse, that will become a function of the na_goodness or priority at some point). We also are investigating how the idle processing is effected. If only cpus in the callings cpu's set are considered in scheduling there is the chance of cpus running idle while scheduable tasks are waiting for cputime. We therefore distinguish between the various cases, namely whether in reschedule_idle() we search for all cpus or not [ i10 ]. Furthermore we distinguish the case where occasional load balancing is turned offor on [ b0/1 ]. The case shown here is for a 4-way system with 4 pools of each 1 cpu. We executed the "make -j12 bzImage" of he kernel build. The plot shows the divergence of the average runqueue length from the mean.